
下記は修正前の記事について書いています、その点ご留意ください!
「侍エンジニア塾」の評判、なにやらよろしくないようですね、気の毒になるくらいに。こんなまとめが作られるくらいには評判が良くないご様子。

個人的には「ちょっと間違いがあるくらいなら、別にまあ、人間のやることですし仕方ないのでは」と思ってスルーしていました。
ですが、ふとしたきっかけでC言語の mallocについての解説記事を拝見する機会がありまして、見てみると、「お…….おおう」となりました。正直なところ、これを見て学習するのはまずいのでは、と。これからエンジニアになろうという方には見せたくないな、と大変失礼ながら、思いました。
といっても、C言語の勉強を始めたばかりのかたにはどこがよろしくないのかわからない気もします。そこで今回は、現場のおじさんエンジニアから見た侍エンジニア塾の記事のツッコミどころを挙げていこうかと思います。侍エンジニア塾の記事を攻撃するのが目的ではなく、それの間違ってるとこをデバッグして、どのようなとこでつまづきやすいのか勉強しようという趣旨です。
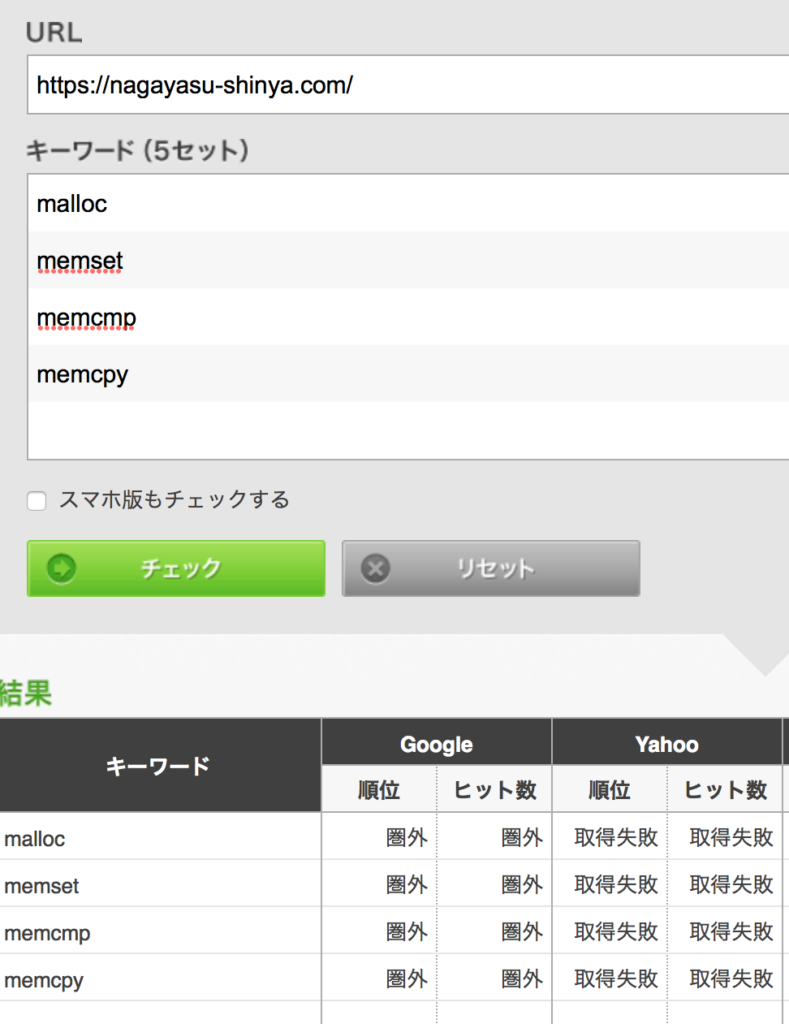
例として「【C言語入門】mallocの使い方(memset, memcpy, free, memcmp)」という記事を見ていきます(たまたま目についたので)。ちなみにこの記事はGoogle検索でトップページに表示されました。参考までに私のブログの検索順位と比較を載せておきますね。
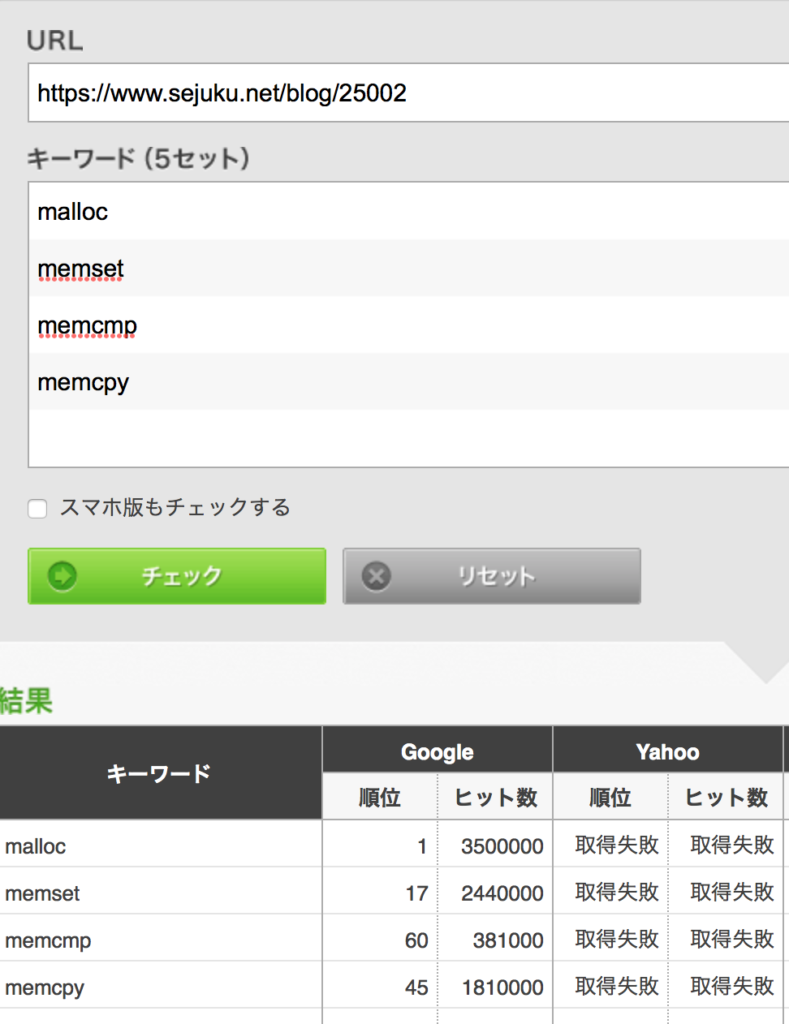
上図は侍エンジニア塾さん。強い。malloc なんていうでかいキーワードで1位ですと。それに比べて弊ブログ(下図)の雑魚さ具合よ……
『memsetの使い方について』の章のサンプルコードにつっこむ
『memsetの使い方について』の章で、下記のようなサンプルコードが記載されていました。明らかなバグや好ましくないとこなど、ちょっと考えて見てください。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 構造体の宣言
typedef struct {
int num;
char *str;
} strct;
int main(void) {
// 実体を生成
strct *entity;
// 動的メモリの確保。確保したメモリをstrct型ポインタにキャスト。
entity = (strct*)malloc(sizeof(strct));
// メンバの初期化
entity->num = 0;
entity->str = (char*)malloc(sizeof(32));
// メモリに文字列を代入
sprintf(entity->str, "%s %s!", "Hello", "World");
printf("%s\n", entity->str);
char arr_str[] = "Hello USA!";
// メモリサイズの変更
entity->str = (char*)malloc(sizeof(arr_str));
if(entity->str == NULL) {
printf("memory error");
return -1;
}
// アドレスの先頭からarr_strのバイト数分だけNULLで書き換え
memset(entity->str, '\0', sizeof(arr_str));
printf("%s\n", entity->str);
// メモリの解放
free(entity->str);
free(entity);
printf("processing completion\n");
return 0;
}
私が「これまずいな」と思ったところを下記に書いてみますね。
メモリリークしてる
下記のコードの中の「メモリサイズの変更」とコメントのあるmalloc、これはだめです。
// メンバの初期化
entity->num = 0;
entity->str = (char*)malloc(sizeof(32));
// メモリに文字列を代入
sprintf(entity->str, "%s %s!", "Hello", "World");
printf("%s\n", entity->str);
char arr_str[] = "Hello USA!";
// メモリサイズの変更
entity->str = (char*)malloc(sizeof(arr_str));
これだと「メンバの初期化」とコメントのあるところでentity->strに確保した領域を指すポインタが1つもなくなってしまいます。
そのためその領域はずっと使われず、freeで解放もされず、ずっと無駄に存在し続けることになります。これは「メモリリーク」という厄介なバグです。この例では数Byteだけなので大したことないですが、これがループでぐるぐる回るようなところにあった場合、どんどんメモリリークしてそのうち(数日後だったり数ヶ月後だったり)不具合が発生します。とても厄介なバグです。
ではどうするのが正しいのか。正解は realloc関数を使うことです。 mallocで確保した領域のサイズ変更は、正しくは realloc 関数を使います。
// メモリサイズの変更 entity->str = realloc(entity->str, sizeof(arr_str));
sizeofの使い方がだめ
sizeof演算子の使い方を間違えています。具体的には下記のコード。
// メンバの初期化 entity->num = 0; entity->str = (char*)malloc(sizeof(32));
これはおそらく32Byteだけmallocで確保したかったんでしょうけど、できていません。sizeof(32) も sizeof(100000) も同じ値になります。なぜなら32も100000もint型なので、結局sizeof(int)となりますから。CPUにもよりますが大抵の環境はint型は4Byteか8Byteでしょう。ということでこれは確保した領域が小さすぎて下記のところで範囲外のところまでデータを書き込んでしまいます。バッファオバーフローという典型的なバグです。
// メモリに文字列を代入
sprintf(entity->str, "%s %s!", "Hello", "World");
たったこれだけのコードで、メモリリークとバッファオーバーフローという二大バグを仕込むなんて、なかなかのツワモノですね。グーでビンタされても文句言えません。。。
『memcmpの使い方について』の章のサンプルコードにつっこむ
『memcmpの使い方について』の章で、下記のようなサンプルコードが記載されていました。ここでもどこがおかしいかちょっと考えて見てください。『memsetの使い方について』のとこで指摘したとこは置いておきましょう。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 構造体の宣言
typedef struct {
int num;
char *str;
} strct;
int main(void) {
// 実体を生成
strct *entity;
// 動的メモリの確保。確保したメモリをstrct型ポインタにキャスト。
entity = (strct*)malloc(sizeof(strct));
// メンバの初期化
entity->num = 0;
entity->str = (char*)malloc(sizeof(32));
// メモリに文字列を代入
sprintf(entity->str, "%s %s!", "Hello", "World");
printf("%s\n", entity->str);
//構造体の実体のコピー
strct *copy_entity;
copy_entity = (strct*)malloc(sizeof(strct));
memcpy(copy_entity, entity, sizeof(strct)); // メンバのポインタは浅いコピー
// コピー元とコピー先を比較演算
if( memcmp(entity, copy_entity, sizeof(©_entity)) == 0) {
printf("構造体の実体%sと%sは同じです\n", "entity", "copy_entity");
} else {
printf("構造体の実体%sと%sは別です\n", "entity", "copy_entity");
}
// 深いコピーにするためには、メンバ単体でコピーが必要
copy_entity->str = (char*)malloc(sizeof(32));
strcpy(copy_entity->str, entity->str);
// コピー元とコピー先を比較演算
if(memcmp(entity, copy_entity, sizeof(©_entity)) == 0) {
printf("構造体の実体%sと%sは同じです\n", "entity", "copy_entity");
} else {
printf("構造体の実体%sと%sは別です\n", "entity", "copy_entity");
}
// メモリの解放
free(copy_entity->str);
free(copy_entity);
free(entity->str);
free(entity);
return 0;
}
構造体をmemcmpで比較してはいけない
そもそもですが、構造体の比較にmemcmpは使ってはいけません。現場でやるとたぶん張り倒されます。各メンバの間をパディングされる可能性があり、そこの値は不定値の可能性が高いためです。詳しくは下記のサイト/記事を参考にして見てください。

構造体のコピーはmemcpyでなく代入を使おう
構造体のコピーにmemcpyを使うのはイマイチです。配列と違い、構造体は普通の代入文でコピーできます。つまり
memcpy(copy_entity, entity, sizeof(strct));
は
*copy_entity = *entity;
と処理的には同じです。
違いがあるとすれば、memcpy は単にデータをコピーするだけなので、コピー元とコピー先の型の不一致をチェックしたりはできません。極端な例ですが
int tmp;
memcpy(copy_entity, &tmp, sizeof(strct));
のように型が違ってもそのまま処理をしてしまいます。一方、代入なら
int tmp;
*copy_entity = tmp;
などとしたらコンパイルエラーが出るのでバグを出す心配がありません。
またコピーするべきサイズも、memcpy なら自分で計算して引数に渡さなければいけませんが、代入ならコンパイラが勝手に計算してやってくれるので、ミスする可能性が減ります。
処理速度を気にする人もいるかもしれませんが、関数呼び出しのオーバーヘッドなどを考えると、素直に構造体のコピーを使う方が賢明です。そこらへんはコンパイラがいいかんじにしてくれます。memcpyの方が早ければ勝手に置き換えてくれますよ。
とうことで、構造体のコピーにはいいことづくめの代入の方を使いましょう。
sizeof演算子は正しく使おう
下記のコード、バグっていますね。copy_entity は 構造体strct型へのポインタ型ですので、©_entityは構造体へのポインタへのポインタ型です。ポインタ型はCPUにもよりますが、4Byteか8Byteですので、先頭のメンバしか比較できない可能性が高いです。
// コピー元とコピー先を比較演算
if( memcmp(entity, copy_entity, sizeof(©_entity)) == 0) {
やりたかったのは構造体全体の比較でしょうから、下記のようになるはずです。copy_entity は 構造体strct型へのポインタ型ですので、*copy_entity は構造体strct型ですね。これで構造体全体を比較することができます。
// コピー元とコピー先を比較演算
if( memcmp(entity, copy_entity, sizeof(*copy_entity)) == 0) {
バグは無視しちゃダメ
このサンプルコードの実行結果は下記のようになると記事に記載あります。実際に上記のコードは確かに(構造体にパディングがなければ)そうなります。
Hello World! 構造体の実体entityとcopy_entityは同じです 構造体の実体entityとcopy_entityは同じです
これは何がしたかったのかというと、おそらく「浅いコピー(Shallow Copy)」と「深いコピー(Deep Copy)」の違いを利用してmemcmpの説明をしたかったんでしょうね。
実際、サンプルコードのコメントを見てみると、1回目のmemcmpは浅いコピー(Shallow Copy)後の比較、2回目のmemcmpは深いコピー(Deep Copy)後の比較をしていることが読み取れます。
ここで「浅いコピー(Shallow Copy)」と「深いコピー(Deep Copy)」ってなんやねん、と思った方もいると思うので簡単に概要だけ説明しておきますね。
浅いコピー(Shallow Copy)というのは、ポインタ変数も含めて全部を、単にコピーしただけです。ポインタ変数の中身はアドレスなので、そのアドレスごとそのまんまコピーした状態です。
例えば entity->str の指すアドレスが0x10000000番地だったとすると、浅いコピーをした copy_entity->str の指すアドレスも0x10000000番地となります。
一方、深いコピー(Deep Copy)をした場合は、ポインタ変数はそのままアドレスをコピーするのではなく、新たに別の領域を確保してそれを指すようにします。
entity->str の指すアドレスが0x10000000番地で、copy_entity->str の指すアドレスは別の領域の0x20000000番地だという感じです。
図で示すと下記のような感じです。浅いコピーは同じものを指し深いコピーはそれぞれに別の領域を指している、という状況です。
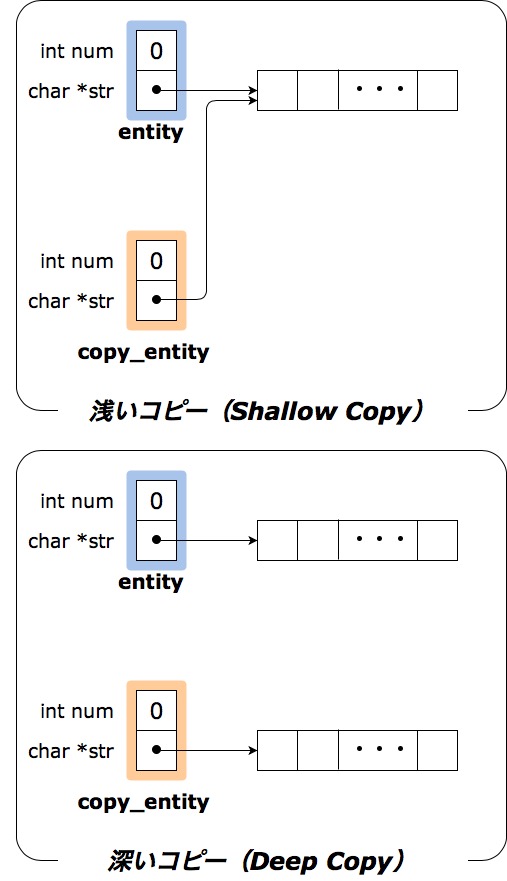
さて、ここまでくると勘のいい人は気づいたかもしれません。そうです、深いコピー(Deep Copy)を行った場合entity->strとcopy_entity->strは異なるはずなんです。だって違う領域を指しているはずなんですから。上記の図を見れば一目瞭然ですね。
でも記事にある実行結果は、深いコピー(Deep Copy)を行った後でもコピー元entityとコピー先copy_entityは同じだとある。なぜか。
「sizeof演算子は正しく使おう」のところで説明した、strcmpのsizeof演算子に渡す変数の型が間違っているというバグのせいです。このバグのせいで構造体の最初のメンバ int numしか比較できていないんですね。
実際、このバグを修正すると、2回目のmemcmpつまり深いコピー(Deep Copy)を行った後のmemcmpでは「構造体の実体entityとcopy_entityは別です」と表示されます。下記はwandboxでの実行例。

浅いコピー(Shallow Copy)と深いコピー(Deep Copy)をmemcmpの例として使った時点で、この結果は期待通りでないとわかったはずです。そこでなぜデバッグしなかったのか理解に苦しみます。のっぴきならない事情があったのかもしれませんが、私にはよくわかりませんね。。。
まとめ
いまをときめく「侍エンジニア塾」のとある記事について現場のおじさんとしていろいろ突っ込んでみました。正直、ちょっとこれはどうよ、と思うバグが多々あったのは否めませんが、バグをなくすことなんてできませんから、ある程度は致し方無いのかなと思います。人間のやることですし。強いて言えば、最後に書いた「実行結果がおかしいとわかっていた(はず)なのにデバッグしていない」という疑念だけは引っかかりますね。私の勘違いならいいんですが。
いま現時点では、該当サイトの記事を読むより本屋に売っているC言語の本を読むほうが確実だと思います。私がオススメするのは下記の記事に書いています。もし本屋で見つけたりしたら手にとって中身を確認して見てくださいませ!

また、少しマニアックなC言語の文法なら下記の記事がお勧めです。ぜひぜひ。
バグを出すのはもう仕方ないんですけど、バグを見つけたらちゃんとデバッグしましょうね。おじさんとの約束だよ!


コメント
reallocでポインタ直接上書きも良くないと思います。nullが返ってきたら悲劇です。
そうですね。本当ならちゃんと一時変数作ってそこで受けないとダメですねぇ。